Spec-tacular: How I Made Multimedia Technical Specifications Easier to Digest
 Łukasz Kita•Dec 4, 2025•10 min read
Łukasz Kita•Dec 4, 2025•10 min readAs mentioned in my Demuxed 2025 recap blogpost, I had the pleasure of delivering a lightning talk about a side project I’ve been working on: automatic knowledge extraction from the H.264 specification. Today, I would like to delve deeper into this topic, sharing more details than I could during the brief three-minute talk.
So, without further ado, join me for a story of my struggle with the H.264 specification and how it led me to seek alternatives!
An alternative way to read specs
Let’s be honest: technical specifications, like those defining video compression standards, can be pretty daunting. They deal with complex technical issues and must ensure that every reader gets a precise, uniform understanding of the underlying concepts.
It’s particularly challenging with standards that have evolved over many years, needing to address backward compatibility while also thinking in advance about potential new features. H.264 is an example of such a dynamic standard. Wouldn’t it be good to have a tool which helps you reason about different concepts defined in the specification?
In the era of AI, using an LLM with a context window large enough to incorporate all the information covered in the specification sounds like an obvious choice. If the context size was the problem, we could use the Retrieval Augmented Generation approach. But one challenge with these methods is that LLMs sometimes fabricate information, making it tricky to confirm the accuracy of the derived statements.
To address this issue, I decided to try separating the direct knowledge extraction from the reasoning part. Specifically, I employed an LLM to transform the information written in human language from the specification into a structured format. The LLM’s task was solely to convert descriptions into a factual database, making it easier to verify its accuracy. Later, using these ‘atomic’ facts, I started making logical inferences about various concepts in a completely deterministic way using a logic programming language called Prolog.
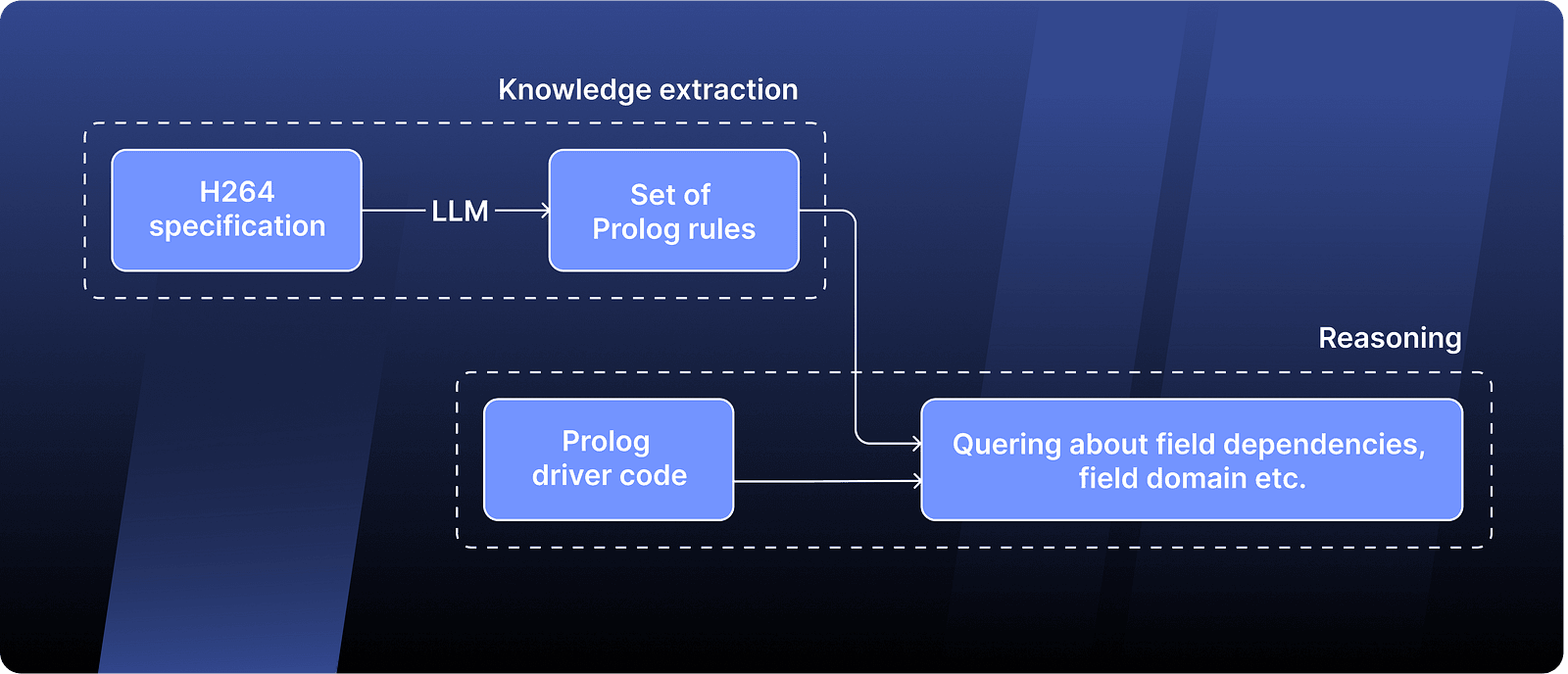
A little bit of a context
Here is the H.264 specification: an 800-page document filled with highly technical text, numerous diagrams, and images.
Now, imagine that your task is to figure out how to calculate resolution of the frames in the video stream. After devoting a significant portion of your precious time for the search, you would realize that what you need is:
CroppedHeightwhen it comes to height of the frameCroppedWidthCwhen it comes to width of the frame
To compute CroppedHeight, you must know the values of FrameHeightInMbs and CropUnitY. CropUnitY can either be almost directly read from the bitstream (if ChromaArrayType equals 0 CropUnitY = 2-frame_mbs_only_flag), or you must first calculate SubHeightC in the first place.
In short, you’d need to pinpoint all these details in the specification:

It’s quite a task, especially when all you wanted was to find out the resolution of the frame, right?
Figuring out how to calculate H.264 frame resolution was precisely the challenge I was given in late autumn of 2021, which was also my first exposure to the H.264 specification. Since that time, I’ve revisited various sections of the specification multiple times, somewhat increasing my understanding of it (I’ve even written a brief tutorial as an introduction to the H.264 codec!). But, despite my better familiarity with the codec, I still thought that having a tool capable of automatically resolving dependencies between the fields would be incredibly useful.
What I wanted to have was a tool capable of responding to the following queries:
- calculation formula for given field
- domain of a field (the range of its all possible values), when specified constraints apply
- default value of the field
- all the fields which values affect the value of a particular field
Turning the spec into data
I began by modeling the fields and their interrelationships within the specification. I identified two main types of fields present:
- Bitstream fields: These are directly available in the stream, consistently noted in
snake_caseand outlined in the specification’s Syntax Table (section 7.3). They always have strictly defined types. An example of such a field isframe_mbs_only_flag. For these fields, I focused on determining:
- Their specific type — such as
u(8)for an unsigned integer occupying 8 bits - Conditions that dictate the field’s presence in the bitstream, consisting of all relevant if-statements and loop conditions surrounding the field’s occurrence in the Syntax Table
- The default value applied when the aforementioned conditions exclude the field’s presence in the bitstream
2. Derived fields: Found across various sections of the specification (also noted within lines of the Syntax Tables in section 7.3). These fields, named in PascalCase, are calculated based on the values of other fields, including both bitstream and derived fields. Examples of these fields are CroppedHeight and ChromaArrayType. For these fields, I needed to obtain:
- The formula used for their calculation
- Constraints, as sometimes the specification restricts fields to specific values only
Extracting information from the Syntax Table was relatively easy because these tables are well-organized. With a simple Python script, I could retrieve the type of a bitstream field and compile a list of all the conditions associated with that field. However, fetching information about the default values and calculation formulas was more challenging, as they were written in human language. This is where I used Large Language Models.
Knowledge extraction using LLM
I know you might be tired of hearing “Retrieval Augmented Generation” or RAG, but I must admit — this is precisely what I used during the knowledge extraction process. Even though modern language models have a big context window and can handle a lot of information at once, the extreme high volume of details in a technical specification can still be overwhelming.
In a typical RAG fashion, I divided my input into multiple “Nodes.” I then transformed each node into a vector and stored these in a vector database. When I had a query for the LLM, I first turned the query into a vector too. Next, I searched the database for vectors close to my query (meaning they’re likely relevant) and used these vectors to add more context to my query, helping the LLM understand better what I was looking for.
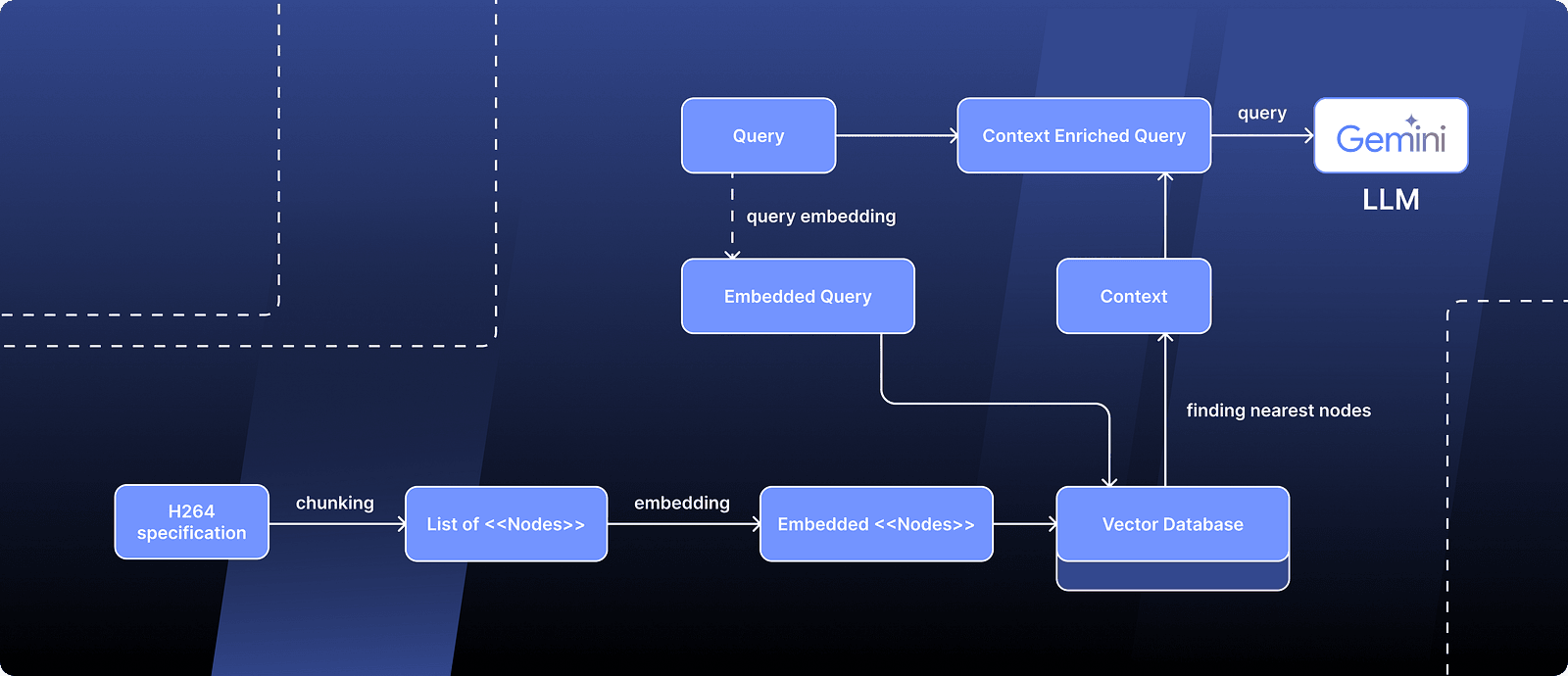
For implementation of the RAG process, I used llama-index. It helped a lot by offering features like vector database integration for storing embeddings, compatibility with various LLM APIs, and the ability to preprocess documents in different formats, such as PDFs with embedded images and tables.
For the generation side, I relied on Gemini 2.5 Pro.
Fortunately, modern LLMs are quite proficient at generating outputs in specified formats — they use it to provide so-called Function Calling API and are specifically trained to generate JSONs. I instructed the LLM to output data in a structure I desired, allowing for more controlled results.
By processing the data step-by-step, I started with the LLM generating JSON with partially processed data. This output then served as the foundation for generating more processed JSON in successive steps.
I quickly found out that the “Generation” part of RAG wasn’t the problem — it was the “Retrieval” section that caused issues. The chunks pulled from the database often didn’t match my queries well, or they lost context too fast. The best fix to preserve context turned out to be using larger nodes and organizing them in a hierarchical manner, using the Tree Index.
Knowledge database in Prolog
In the final stage, I instructed the LLM to take input from the generated JSON files and produce the following Prolog facts and rules, which allow us to model the knowledge detailed in the specification:
f/1, f/2
f(dFlat_4x4_16(K)) :- K #>= 0, K #< 16. % scan arraytype/2— This defines the type for a field, specifying its data format. For example:
type(f(profile_idc), u(8)). % unsigned integer on 8 bits
type(f(chroma_weight_l0(I, J)), se(v)). % signed integer written in ExpGolomb notationconstraints/2— These specify additional value restrictions for a field beyond its basic type constraints. For example, the specification states that elements ofchroma_weight_l0array must be in range between -128 and 127:
constraints(f(chroma_weight_l0(_I, _J)), X) :- X in -128..127.default_value/2— This defines a default value for a field if the input doesn’t specify one, often when conditional logic is involved. For example, default value ofchroma_format_idcis 1 and it can be expressed as:
default_value(f(chroma_format_idc), 1).calculate/2-This determines how to compute the value of a derived field based on other field values. For exampleMbHeightCfollows this formula:
calculate(f(dMbHeightC), Value) :-
domain(f(chroma_format_idc), Chroma), Chroma \= 0,
domain(f(separate_colour_plane_flag), 0),
domain(f(dSubHeightC), SubHeightC),
Value #= 16 // SubHeightC.depends_on/2default_value/2andcalculate/2rules, explicit listing avoids complex metaprogramming. Examples:
depends_on(f(dMbHeightC), [f(chroma_format_idc), f(separate_colour_plane_flag), f(dSubHeightC)]).An observant reader might notice that in the calculate/2 definition I used the domain/2 rule.
This rule helps determine all potential values a field can take, considering constraints, types, and default values (you can think of it as a kind of an “actual” value of a field at any given moment).
With the following “base” facts and rules and the domain/2 rule definition, I could start generating more complex rules.
One of the advantages of using a logic programming language is the ability to run queries during development. For example, with the following query:
f(F), \+ type(f(F), _T).I could detect any fields within our model that haven’t been assigned a type. Identifying these omissions allowed me to manually update our knowledge database.
Results
After inspecting the Prolog rules generated by the LLM and refining them a few times, the knowledge database was ready to go!
Using just the following few lines of Prolog code and the rules we defined before, I was able to generate a Mermaid graph that clearly displays the dependencies between the fields used to calculate the desired field value.
generate_mermaid_graph(Field) :-
writeln('graph TD'),
generate_edges(Field),
nl.
generate_edges(Field) :-
depends_on(Field, Dependencies),
generate_edge(Field, Dependencies),
true.
generate_edge(f(_Field), []) :- true.
generate_edge(f(Field), [f(H)|T]) :-
format(' ~w --> ~w~n', [H, Field]),
generate_edge(f(Field), T),
(is_dependent_field(f(H)) ->
generate_edges(f(H));
true
).This is how the rendered graph looks like for the CroppedWidthC field:
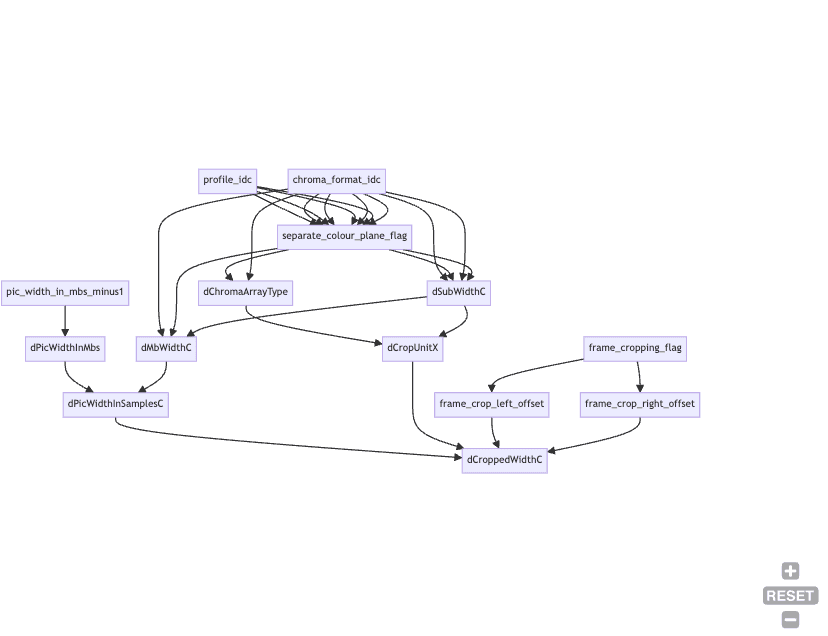
In a similar fashion, we can analyze all potential values that a given field might assume.
If we run a query for CroppedWidthC without any additional constraints applied, we see that this field might assume any value.
?- domain(f(dCroppedWidthC), CroppedWidthC).
% OUTPUT: CroppedWidthC in inf..supBut if we restrict the profile to main (indicated by profile_idc equal to 77) disable the cropping flag and run the query again:
?- set_value(f(profile_idc), 77),
set_value(f(frame_cropping_flag), 0),
domain(f(dCroppedWidthC), CroppedWidthC),
% OUTPUT: CroppedWidthC in 8..supWe can see that only possible values for this CroppedWidthC must be greater than or equal to 8!
If you’re curious to explore the knowledge database yourself, as well as see more implementation details, I’ve set up an online Prolog notebook with an H.264 playground. Here, you can try out the examples I’ve shared and more, right on your own!
Final thoughts
The knowledge database might contain some errors (I am pretty sure it still does!). The biggest challenge during the project was designing a model that effectively captures and translates all this knowledge into Prolog relationships.
The model I developed isn’t perfect and it definitely doesn’t capture everything, but I still think it proves the point that an alternative way of working with technical specification is possible.
We are Software Mansion — multimedia experts, AI explorers, React Native core contributors, community builders, and software development consultants. Need help with building your next dream product? You can hire us.