
Retrieval-Augmented Generation Explained
 Piotr Zborowski•Aug 27, 2025•10 min read
Piotr Zborowski•Aug 27, 2025•10 min readWhen using large language models (LLMs), we rely on their factual knowledge — while their ability to use human language is helpful, it wouldn’t be much without access to information about the world. That’s where retrieval-augmented generation comes in. Keep reading to see how it works, along with its benefits and limitations.
Knowledge in an LLM
The most fundamental way in which LLMs acquire knowledge is their training process — they are trained on vast collections of text, known as corpuses, which both hold factual information about the world and follow the rules of natural languages like English, French, Chinese and so on. Corpuses can contain books, dictionaries, articles, posts, websites, essays, newspapers, transcripts, interviews, lectures — and even this post.
The obvious limitation of training LLMs on static datasets is that they can only reflect information available up until the model’s training date. Models aren’t retrained daily, and are used for months or years after their launch, so there is a knowledge cutoff — the last point in time their training data covers. For example, GPT-4o’s cutoff is October 2023, Claude 3.5 Sonnet’s is April 2024, and LLaMA 3’s is March 2023.
What if LLMs don’t have up-to-date knowledge?
What if you ask a model about something it didn’t really learn during training? Most likely, it won’t admit it — the goal of an LLM is to provide an answer that looks accurate. If it lacks information, it’ll hallucinate, which means it’ll provide outputs that are incorrect, nonsensical, or factually untrue, despite appearing plausible. There are use cases where LLMs are especially prone to hallucination — for instance, if you ask them to recommend books about a certain topic.
The answers can also be wrong for other reasons. Even if the information is actually provided in the corpus, it might not be true, since the data can come from unreliable sources. Another risk we face is terminology confusion. Oftentimes, words have multiple meanings — LLM could mean a large language model in the field of natural language processing, but it could also mean logic learning machine. Unless the question provides enough information explicitly, the model can confuse terminologies from different fields.
Context is everything
When a model doesn’t know enough, the simplest fix is probably to provide it with the needed information. You could simply paste the text on the topic and ask the LLM to rely on it. It greatly reduces the risk of hallucination — the goal of the model is to present a plausible answer and in order to seem plausible in the face of additional information about the topic, it has to be coherent with it.
To put you in the picture: if you ask a model with a knowledge cutoff in 2021 which country won the indoor volleyball men’s tournament at the Summer Olympics in Paris in 2024, the US seems a plausible answer since they won in 2008. However, if you provide it with the list of the winning representations first, saying that the US won would be incoherent with the list (since it was France that won), the answer would not seem plausible anymore.
Why manual context pasting isn’t enough
The approach described above comes with a number of issues:
Costs
Including vast amounts of text in your query comes at a price — that’s more tokens and higher costs from the provider if you use cloud-based AI, or more computation if you use local AI.
Focus
The larger the context, the harder it is for the model to focus on the right bits of information. Manually striking a balance between information load and prompt size may be difficult.
Live context
Your task may require information that keeps changing live — copying and pasting it with each query would increase the token count even further and would simply be troublesome for users.
You don’t know what you don’t know
You may simply not know what information is needed to solve the task at hand. If you do know where to get the data from, then the LLM’s job pretty much comes down to summarizing it. What we want is for the model to bring in data that fits our problem, just like it does with the knowledge from training.
Retrieval-augmented generation — what is it and how it helps
Retrieval-Augmented Generation (RAG) solves many of the above challenges. At its core, it provides the model with documents containing high-value, authoritative data, from which the most suitable fragments of text are extracted and automatically added as context to your query.
Apart from the knowledge from the foundational model — LLM trained on some corpuses — you can easily access outside, authoritative, up-to-date knowledge and use it for market analysis, customer support, product development, research, knowledge engines, recommendation services, document summarization, and much more.
RAG offers a number of advantages over plain foundational LLMs:
Customization
Thanks to RAG, you can provide the model with your own important data for tasks you’re interested in, without relying on the corpuses the model has originally been trained on. Almost any business can supply the model with their specific manuals, logs, or knowledge bases for improved performance.
Convenience
The framework automatically handles retrieving important information based on your queries — you don’t have to worry about pasting anything into the chat, which is not only tiring but also makes the text harder to read.
No need for retraining
The model doesn’t have to be retrained (which can take months for state-of-the-art LLMs!) just for the sake of gaining new knowledge.
Current information
With RAG you can create another process, which continuously downloads new information like the weather, and have it retrieved during your chats live.
Cost and precision
Retrieval-augmented generation pipeline doesn’t load the entire knowledge base at once — only the bits that are important for your query are retrieved, allowing the model to both use less tokens and focus better on data that actually matters.
Source attribution
You can further reduce the risk of the model hallucinating by asking it to provide source attribution, which is made possible with RAG.
Developer control
Modern-day applications require more and more data — with RAG, developers can grant and revoke access to specific information at any time or create sophisticated workflows generating new data for the LLM to use.
Scalability
Thanks to the automation of retrieval and fixed chunk length, RAG is way more scalable than plain pasting texts into the query. The architecture allows for extremely fast retrieval of important parts of the documents.
How RAG actually works
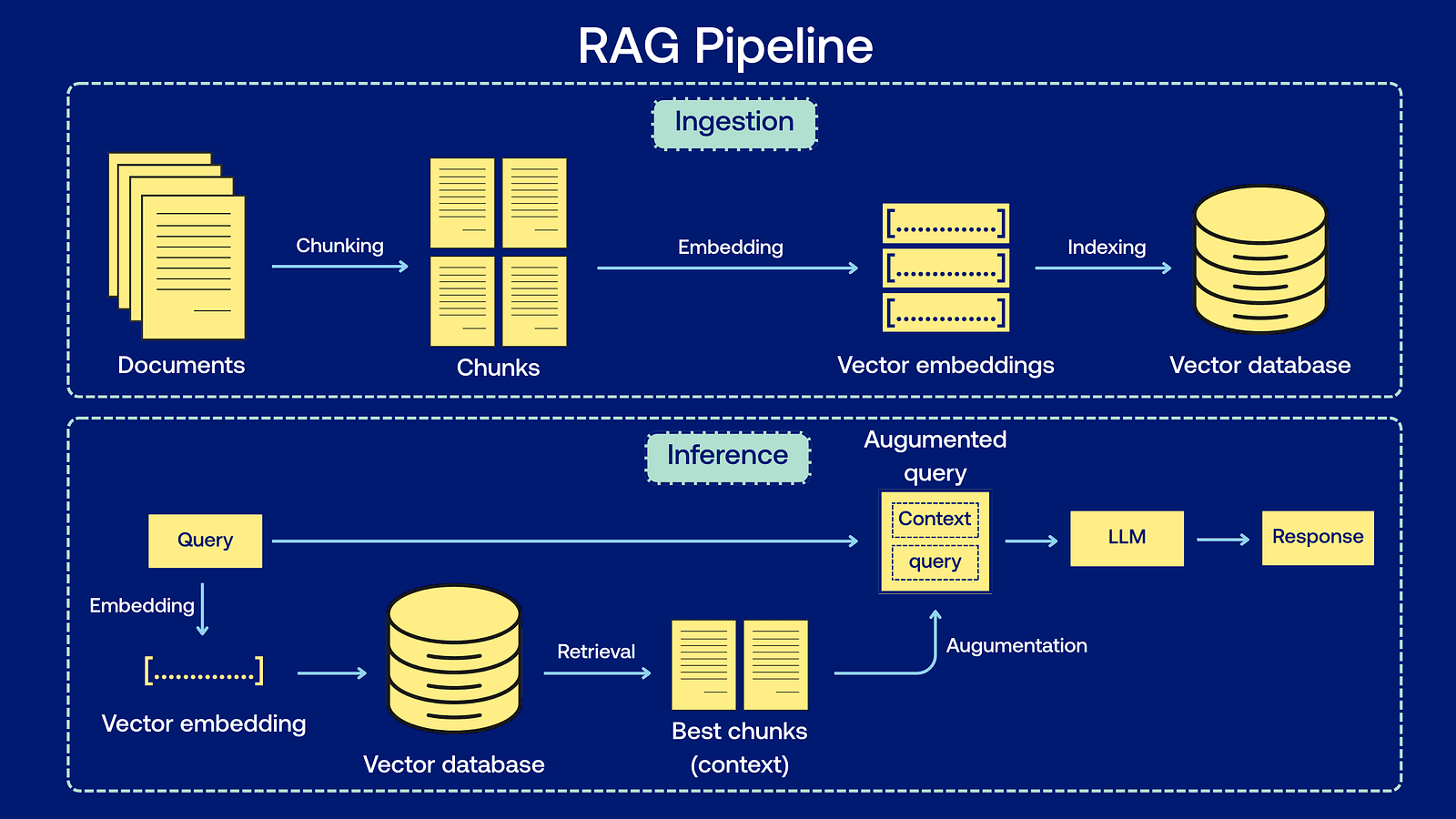
RAG consists of two main stages: the ingestion stage, where documents are prepared for retrieval, and the inference stage, where the user interacts with the model.
The ingestion stage
At this stage, knowledge must be prepared for both fast retrieval and effective processing by the LLM:
Chunking
Since the goal is to retrieve only important fragments of large texts, we simply need to split the text into chunks. For further examples I’m going to use a short sentence — “The quick brown fox jumps over the lazy dog” — instead of actual texts, just for readability, but remember that it’s usually done for larger texts.
For example, you could split it every three words, which would result in chunks: “The quick brown”, “fox jumps over”, “the lazy dog”.

However, when splitting text, we can’t be sure we’re dividing it at the right points to separate sentences by meaning, so we use overlapping segments as a precaution. If we split the sentence into six-word chunks every three words, we would end up with sentences: “The quick brown fox jumps over”, “fox jumps over the lazy dog”.

This already seems to convey more independent information. With this technique, the fragment “fox jumps over” appears in two sentences, allowing us to later choose the one that fits best.
Word embeddings
Then, we split the sentences into tokens — small units of text which convey semantic information, most usually this corresponds to individual words. In our example, the sentence “The quick brown fox jumps over” would be split into tokens “The”, “quick”, “brown”, “fox”, “jumps”, and “over”.
Unfortunately, computers don’t simply understand written words. In order for the LLM to process them, we need to represent them as numbers (more precisely — as vectors, which is math lingo for a list of numbers). Given a list of n words, the simplest way to represent them is as one-hot encoding. The token is represented by a vector which consists of all zeros and one on the position of the token. For example, if our tokens were “The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, and “dog” we could enumerate them and token “fox” would be represented as a vector [0,0,0,1,0,0,0,0,0].

There are two main problems with this way of encoding. First, modern models contain too many tokens and storing them as one-hot vectors would use up too much space. Second, this representation tells us nothing about the relationship between different tokens.
There is a better way — use word embeddings. They also represent tokens as vectors, but they have a fixed, smaller size, and contain any real numbers, not just zeros and ones. For example, “fox” could be represented as [0.73, -0.15, 0.2]. Don’t worry, we’re not going to dive into the nitty gritty details of how to compute such embeddings, you can check out this article from Google if you’re interested. Just know that thanks to this representation we can efficiently capture and compute semantic relationships between different tokens.
Vector database
The embeddings of text chunks are then stored in a vector database with indexing, which allows for a quick retrieval of the most appropriate chunk(s) without the need to compare our query with all the stored chunks.
The inference stage
Once the external data is encoded and stored, we can move on to answering the user’s questions, which involves the following stages:
Retrieval
When the user asks the question, it’s converted into an embedding form too (this time without splitting into chunks, just tokens), and the chunk(s) which is deemed useful as context is retrieved from the vector database. There are various ways to decide which chunk to return, the simplest being to choose the one that is closest semantically.
Augmentation
Once the context is retrieved, it’s appended to the user’s query.
Generation
Now, LLM is activated on the prompt from the user, containing both the question itself and the retrieved context.
Hardships of RAG
You should keep in mind that RAG doesn’t come without its limitations, which concern:
Privacy
Cloud-based AI requires sending your demands over to a remote LLM provider, so if you use your company’s internal data, it means sending that too, which could be a privacy concern. However, you can also use RAG locally — check out our article for an introduction to local AI and its benefits and learn more about our React Native RAG tool for local and offline RAG implementations.
Connection requirement
As all other cloud-based AI frameworks, non-local RAG requires internet connection to work.
Latency
Retrieval increases latency — this effect is minimized by the use of a vector database, but RAG will still work slower than the plain foundational model.
Retrieval quality
Results from RAG depend heavily on the quality of external data we provide. If it’s low quality, appending chunks of it to your query can even spoil the results further.
Knowledge base maintenance
Stating the obvious, but external data has to be maintained, so that it doesn’t become obsolete too.
Costs
Even though RAG is more efficient than pasting large texts into the prompt, it still requires more tokens than plain LLM for the same query, which can increase costs unless you’re using a local LLM.
How to get started?
If you’re interested in developing your own applications using retrieval-augmented generation, be sure to check out the Agents Course on Hugging Face — it covers AI agents (LLMs with access to external tools) more broadly, but it also contains great chapters about RAG and using it in Python with various frameworks. You can try their code snippets on Google Colab and pass quizzes to make sure you remember the information from the course.
You can also develop local RAG applications with our React Native RAG, which solves several of the development hardships you may face. And if you don’t have tech-savvy people capable of React Native development, you can always reach out to us for help at projects@swmansion.com.
We are Software Mansion — software development consultants, a team of React Native core contributors, multimedia and AI experts. Drop us a line at projects@swmansion.com and let’s find out how we can help you with your project.