
Elixir Stream Week: how NOT to load test during a live Elixir-run broadcast watched by hundreds of…
 Karolina Kulig•Dec 2, 2024•15 min read
Karolina Kulig•Dec 2, 2024•15 min readSo, as the title says, we did a thing… But let’s start from the beginning.
Some time ago we came up with the idea of Elixir Stream Week — a week full of Elixir broadcasts led by top Elixir devs, all streamed using Elixir Software. We wanted to achieve two main results. The first goal was to let more people know about Elixir WebRTC — a batteries-included WebRTC implementation for the Elixir ecosystem that we have been working on for some time now. Streaming Elixir content using Elixir WebRTC software sounded like the perfect idea to build some interest amongst Elixir devs. We could also treat each stream as a live demo, showing how the product works — two birds with one stone.
The second thing that mattered to us was the community-building aspect. Community building is at the core of all our efforts, so the idea of an open-for-all week of Elixir broadcasts sounded very exciting to us. We wanted everyone to be able to join in, make themselves comfortable, turn on the broadcast, and tune in to the streams in a laid-back atmosphere. Very casual, not too big. Let’s assume a peak of 100 people — half of what José had on his Twitch streams. Easy peasy, right?
Right..?
Let us take you through the journey of organizing Elixir Stream Week — from the very beginning, through the smaller and bigger hiccups on the way, and finally, how it turned out — both behind the scenes and from the viewer’s perspective.
Step one: pitching the idea to the devs
We came up with a shortlist of Elixir devs who we’d love to see taking the virtual stage. We aimed big, even though we were not sure at first if we’d get any replies. But with each new positive response, we started to get more and more convinced that we were not the only ones excited about the idea, which felt great!
Our final list of speakers looked like this:
- José Valim — creator of Elixir
- Mateusz Front — co-creator of Membrane
- Chris McCord — creator of Phoenix
- Jonatan Kłosko — creator of Livebook
- Filipe Cabaço — Elixir dev at Supabase
There was no other way to put it — the lineup was simply fire.
Next step: preparation time
One of the main assumptions of Elixir Stream Week was to create a community event that would be truly open to all. Since a lot of our work is open-source, we know how important knowledge- and experience-sharing is. We wanted everyone to be able to simply join the streams — no paywalls, no signups required, just click and play. We were also aware that some people would appreciate additional reminders regarding the streams, so we created a simple mailing list — no spam, just updates about ESW.
From the technical point of view, Elixir Stream Week wasn’t the first thing we were going to stream using Elixir WebRTC or to be more specific using Broadcaster, which is a simple streaming platform built on top of Elixir WebRTC. We have already transmitted RTC.ON conference and two other events, each 30–50 people large. Everything went smoothly and since this time we were expecting just a few more people (something around 100–150), we focused on adding a couple of new features like: multiple streamers or chat moderation. We also had load tests on our roadmap but their priority was rather low. The plan was to end all programming work one week before the event.
Three weeks to go — the hype is real
Three weeks before the start of the event we announced Elixir Stream Week to the public, and once we did it, we noticed that the newsletter sign-ups are quite popular. We saw a bit of hype, but at the same time, we thought that it would not grow much from there.
Here’s a sneak peek of what our Slack convo looked like:
Karolina: Hm, there are almost 80 people signed up for updates already — looks quite nice!
Michał: That’s cool, should we share the number with the speakers?
K: Let’s wait till it gets above 100 (probably won’t happen soon)
a few moments later
K: Well, there’s a 100…
With each day, we saw an increase in the number of people signed up for updates. Seeing the number grow, we started to develop a contingency plan. What happens if many people want to join at once, what if the stream suddenly crashes, how do we communicate with people when we lose connection, what if someone decides to do stress tests while we’re live — we wanted to be 100% prepared.
Someone could say: you had three weeks, that’s so much time. And that’s true! But we already had some in-progress features and we had to finish them first as they became crucial for the whole event.
So, the final days before the start of Elixir Stream Week, we were still making a lot of changes to the Broadcaster: adding some logos so it looks nice, adding the mute option so people can see that streams are muted by default, adding slow mode so our chat won’t explode.
We also looked into load testing and started benchmarking our platform using Whepper — a simple tool that we wrote in Elixir to test WHEP servers. These tests quickly showed that the scale can change everything. First of all, our server was not configured with enough file descriptors so we couldn’t even open more than 500 connections.
Next, we observed that when we connect bots really quickly, the time needed to establish the connection grows and accumulates with the number of bots we run. For example, the first bot needed 50ms to connect, the next one 100ms, the next one 150ms and so on. The last bots were just timing out. It turned out that’s due to our main GenServer process (called PeerConnection), which we spawn for every participant. It takes some time to be initialized and because it is spawned under a DynamicSupervisor (spawning under DynamicSupervisor is sequential), when we try to connect multiple people at the same time, their processes are queued. The fix we introduced was to move GenServer’s initialization to the handle_continue callback. If you are interested in more details see this commit.
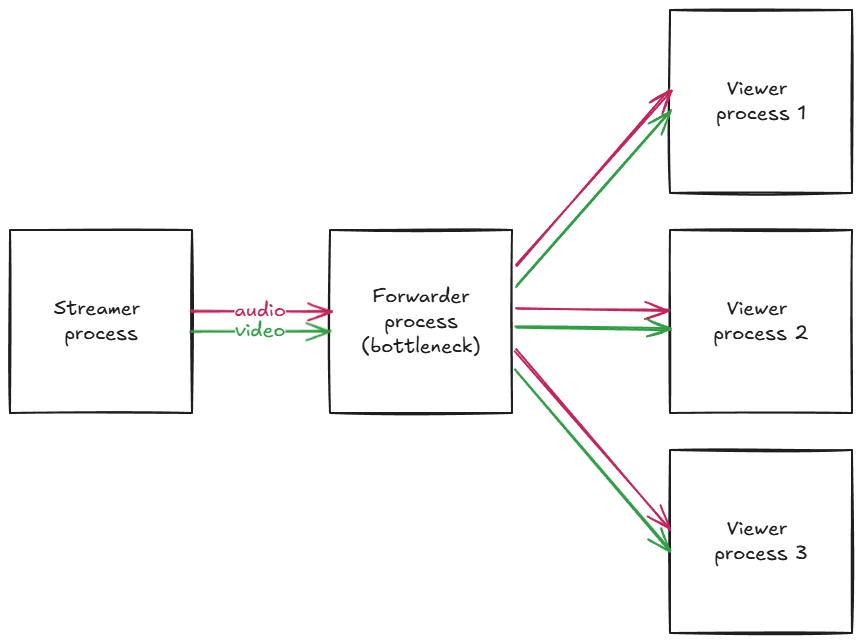
Finally, we estimated that our server should be able to handle 1000 participants having about 67% of our 32/64 CPU usage, and 1.5Gbps of total throughput (we needed to use a machine with a dedicated 10Gbps connection link). The bottleneck was the routing process responsible for forwarding audio and video packets from a streamer process to the viewer processes. However, because 1000 was a pretty big number, we decided to just add a viewer limit to make sure our server won’t explode. If more people come, we will prepare ourselves better for the second day.
A couple of last hours were allocated to researching what we can do about DDoS attacks having only Nginx on board and completely forgetting that we also have Cloudflare… (read this at your own risk.)
Ready, set, go
Starting big, our first streamer was José Valim, who was about to announce what’s new in Elixir v. 1.18. Two hours before the actual broadcast, we went in with a test stream. Everything looked great, the latency was super low, and there was a slight issue with the size of the presenter’s screen, but nothing that can’t be quickly fixed with CSS. A quick server restart and we were good to go.
Half an hour before the stream we started to realize that recording the stream with our current setup (we were using OBS) might be an issue. Nothing to worry though, we managed to come up with a different way of recording and all seemed to be good.
20 minutes until the start of the stream. We opened the Broadcaster just out of curiosity and noticed that 70 people were waiting for the stream. Nothing was happening on the stream yet (apart from the chat excitement) and we haven’t even sent a reminder email to the newsletter group, let alone reminders on other channels. We knew that the number of viewers would exceed our initial expectations, but seeing it grow right before the stream was a bit surreal.
Starting with a bang… and a fail
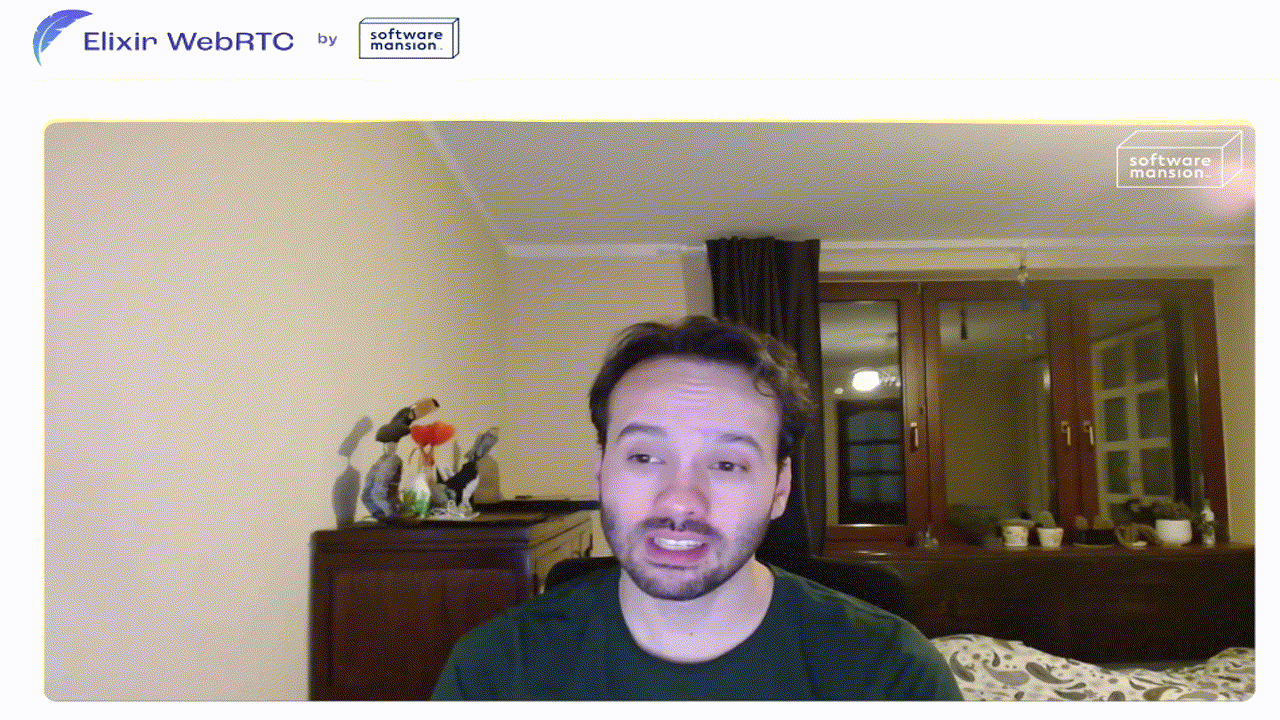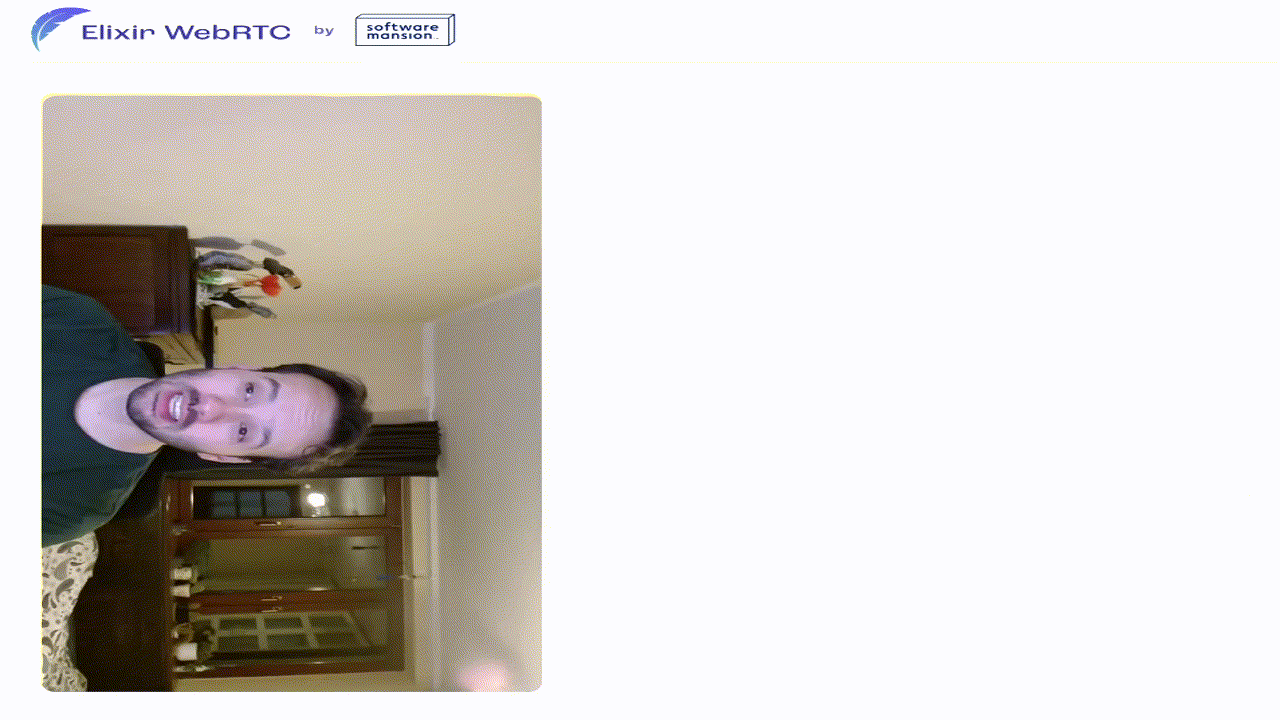
We started the first stream with a quick introduction on our end and then we moved on right to José’s stream. Everything seemed to go smoothly.
The first minutes of the stream go by and we start to notice a very slight flickering of José’s screen. At first, we were not sure if this was just an issue on our end (we thought that it may be caused by the stream recording setup). Unfortunately, we didn’t have to wait long for chat’s reaction.
What was a slight flickering at first turned into visible screen rotations, happening more and more often. This was literally the first time we saw such a thing — throughout five years of working with multimedia, we’ve never seen a rotating video. On top of that, we started to notice some audio glitches as well. We had no idea what was happening. All WebRTC metrics were correct, no error logs on the server side, changing the network didn’t help, refreshing the page a couple of times made things even worse as we started getting 500 response codes.
We didn’t know what to look at — a growing viewer number, hitting over 400 people at that time, or chat history, where people were continuously reporting issues on their end. What was a bit of consolation was that some watchers were writing that the stream looked good on their end. On the other hand, this just added to the unknowns of why the problems were occurring in the first place. José continued his presentation, probably not even aware of the chaos that started to happen on the live. We had an admin-speaker chat that was reserved for emergencies where we could ask José to stop the stream. It was a tough call — after all, a part of the audience could enjoy hearing about Elixir v1.18 updates without any bigger disruptions.
But screen flickerings did not stop — if anything, they started to get worse each minute of the stream. Something had to be done — so we decided to cut the stream for a moment and let José restart his setup (one of the hypotheses was that the problems were caused by something on the speaker’s end). In the meantime, we hopped back on the stream so that we could explain to the audience what was happening and fill in the gap in streaming.
The restart did help a bit. José managed to point to the source of his audio problems and fix them — which meant one less worry on our side. We did lose some of the viewers in the meantime, but we still had around 350 people watching the stream. However, the screen rotations continued to happen and we still didn’t know what was going on.
We managed to get to the end of José’s presentation, followed by a great Q&A. At the end of the broadcast, we had mixed feelings — on the one hand, it was awesome to see all the people coming, asking questions, and even helping us with debugging at some moments. On the other hand, the quality of the broadcast definitely wasn’t the best. And we still had no idea what was the reason for that.
Licking the wounds (and fixing the bugs)

Monday evening and all day Tuesday was a time of fixing everything we experienced during the first stream. We picked three most burning issues: video rotations, service unavailability, and stream recordings. Let’s analyze them one by one.
Testing new Nginx rules on the day of the transmission wasn’t the best idea. We decided to replace them with Cloudflare’s DDoS protection, which was as easy as toggling a single option in the Cloudflare admin panel for our domain.
For recordings, we used Background Music, which allowed us to redirect system audio to a virtual input. This input can then be selected as an audio source in QuickTime Player. The only thing we had to remember was to unmute the stream before starting the recording.
The last problem — video rotations — was much more challenging.
The first idea — that’s due to packet loss. We were losing packets containing some metadata, and as a result, the decoder couldn’t determine the orientation of a video frame. However, this theory didn’t explain why changing browsers helped some users or why we observed different behavior on two computers connected to the same network. Moreover, we had never seen packet loss that resulted in video rotations, even up to 30%.
Next idea — José’s stream was corrupted. But if this was the case, everyone should have experienced video rotations exactly at the same points in time.
Layout problems? Someone suggested HTML layout or CSS settings might be the cause; however, removing everything but the video player didn’t help either.
Keyframe debouncing? When a couple of people join at the same time we send multiple keyframe requests, which increases video bitrate and can trigger packet loss. But again, we have never experienced packet loss that leads to video rotations.
We, of course, couldn’t reproduce the error. Even José was unable to reproduce it after the stream. What should we do? So many ideas and only a couple of hours left till the next stream.
Instead of relying on a lucky strike, we decided to provide ourselves with the data that will help us determine whether the problem lies on the streamer-to-server line or server-to-viewer line. This meant dumping all audio and video packets that our server received from the streamer. If the problem occurred again, we would have raw RTP packets that we could process offline and see what we actually get. We also decided to move from H264 to VP8 codec.
We started a new round of tests at 5PM, two hours before the second stream. There were no visible problems, but so was the case on day one. We added 600 bots to the test stream and asked Mateusz Front, our day 2 speaker, to read a random passage of text about dishwashers to see whether we could notice any latency issues, audio glitches or screen flickering. All good, no problems.
One thing we were especially grateful for was the community and their reaction to all that was going on. Not only did people help us debug — they also did backup recordings and put them out on Reddit and YouTube so those who missed the stream or had a lot of issues with it did not miss out on the content presented by José. Everyone knew about the problems and we did our best to make everything work despite them.
Before the day 2 stream, we were a bit apprehensive about what would happen, but in the end we also wanted to see if what we did trying to debug the Elixir WebRTC stream helped at all. And to reproduce that, we once again needed a significant number of viewers watching the stream. We posted on all of our channels that we think we fixed the bugs, and that it would be great if people would like to join us again to see if we were right.
We started the stream — everything went smoothly, the screen rotations were gone, and there were no audio problems. A huge weight was off our minds.
The only oversight was that we forgot to unmute the stream before starting the recording (funnily, the only thing we had to remember about) but thanks to packet dumps we could very easily recover missing audio from the server.
Days three, four, and five
Since the problems were gone, we could finally relax a bit about the technicalities and focus on what was the best part of Elixir Stream Week — the community, knowledge sharing, and mutual excitement about the streams. Watching Chris successfully live-coding a Twitch clone on Wednesday, seeing all the questions flowing Jonatan’s way on Thursday, and following a brilliant presentation about Supabase’s Elixir adoption stories by Filipe was simply great. With each stream, the number of people signed up for ESW updates grew — which only reassured us that we’re doing something very, very cool.
Elixir Stream Week in numbers
For those who prefer numbers over text, here are some stats on Elixir Stream Week.
- Almost 700 people signed up for ESW updates
- We had a peak of 409 viewers during José Valim’s stream
- Elixir Stream Week was watched from 42 countries
- The whole event was running on a single 32 cores, 64 threads machine
- We had around 30% CPU usage and almost 700 Mbps of total throughput at the heaviest moment
Retro
Every project should be followed by some kind of a retro — here are some of our notes!
What went well:
- the attendance was great — we really didn’t expect so many of you!
- the whole atmosphere, chat activity, and willingness to help in debugging our issues were priceless
- presentations were awesome — we created lots of useful content that keeps getting traction over a month after ESW
- introducing packet dumps allowed us to restore missing audio
What could be improved:
- performing load tests as soon as possible — from now on, we know that’s the most important thing to do. You can have slightly worse UI or UX but you MUST make sure your service will handle the upcoming traffic
- finishing work a week or two before the final launch. Make sure that all tests, bugfixes and rounds of feedback will be done early enough. Spend the last two weeks just promoting the event.
- if that’s possible, run tests with real users, not only with the usage of benchmarking tools
- make sure to persist at least basic metrics (like HTTP response times or status codes)

See you soon
Once again, thanks everyone for joining us! We hope to see you again soon. If you missed any talks, here is the full ESW YouTube playlist, including the screen rotations, chat history, and, most importantly, lots of great learnings from José, Mateusz, Chris, Jonatan & Filipe.
If you’d like to keep up with our work, we’re doing a monthly newsletter dedicated to all things multimedia, streaming, and WebRTC. One email per month, no spam included. See previous editions and sign up here.
And if you need some help with a product that’s related to Elixir, WebRTC, or multimedia, we can work on it together! Drop us an email at projects@swmansion.com, or fill in our contact form and tell us what we can help with.
Happy streaming!
Michał Śledź & Karolina Kulig from Software Mansion